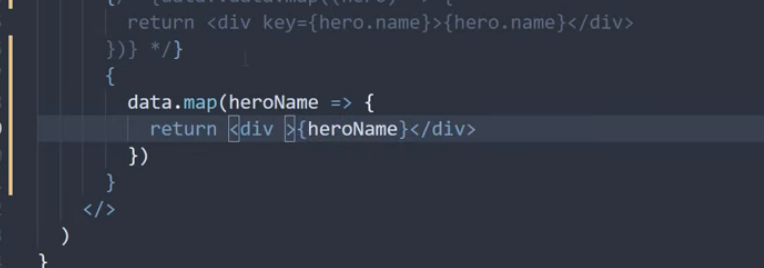
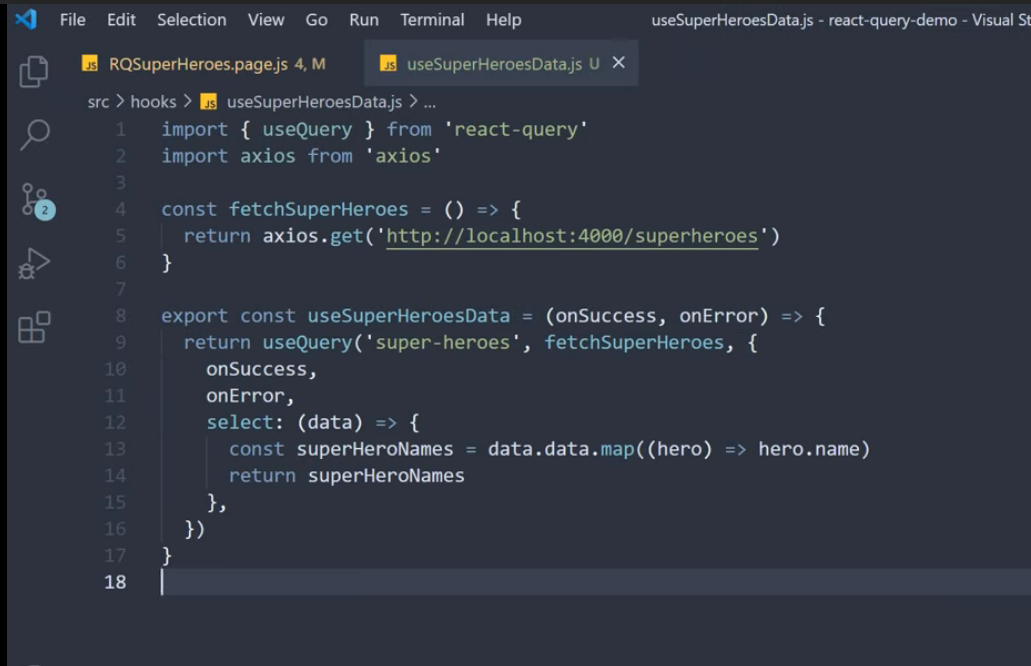
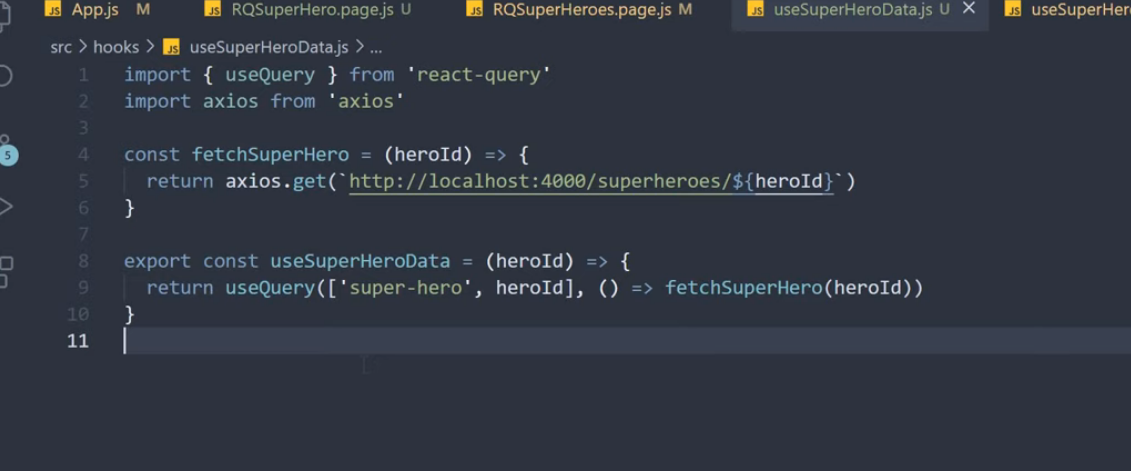
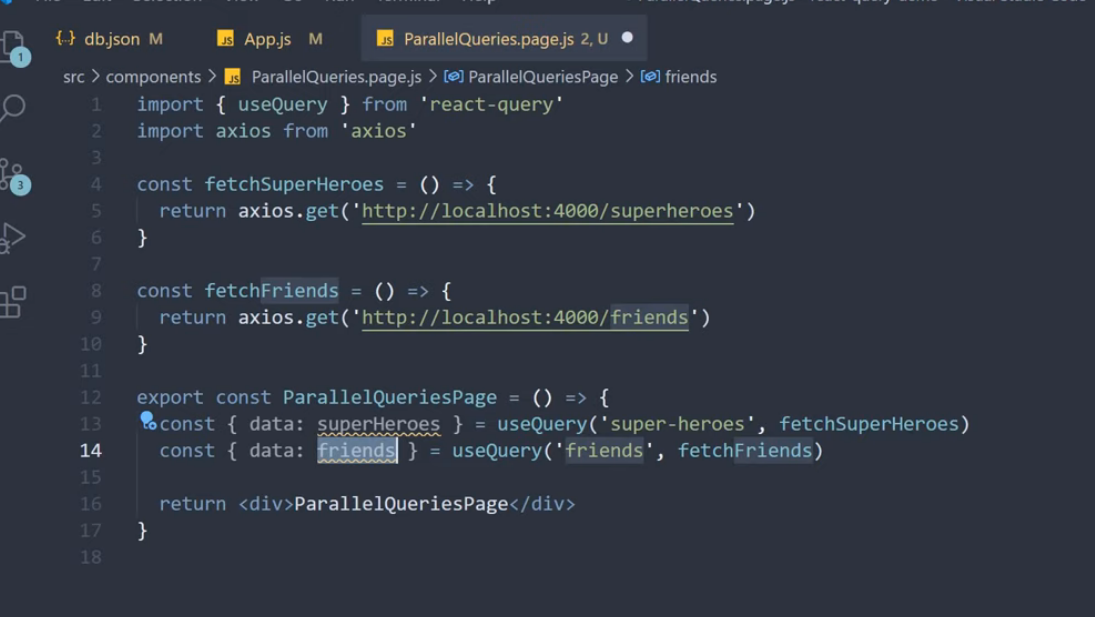
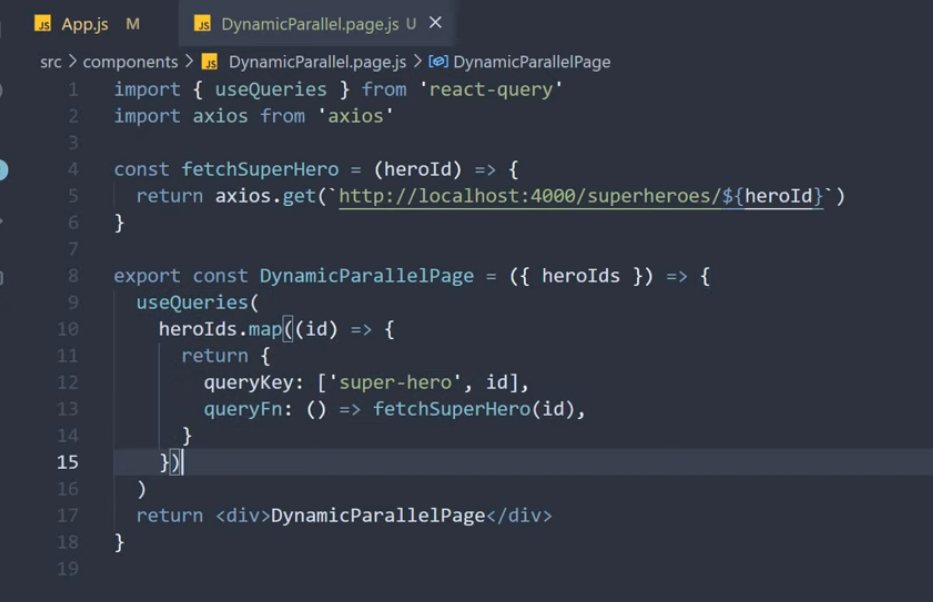
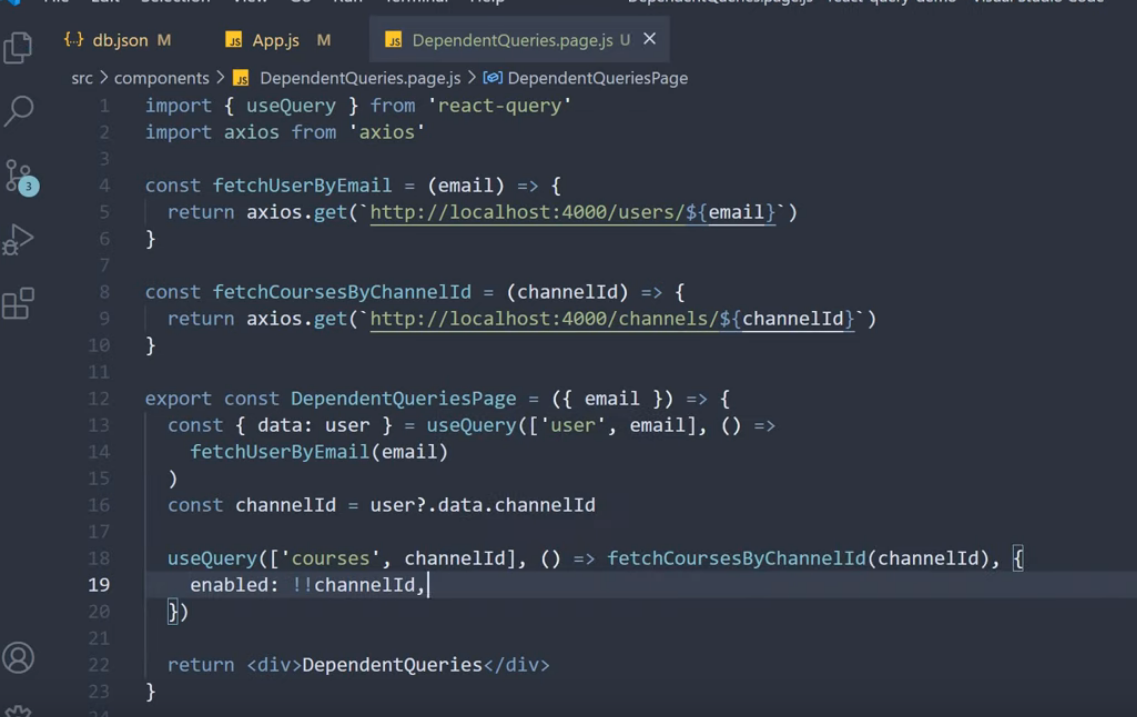
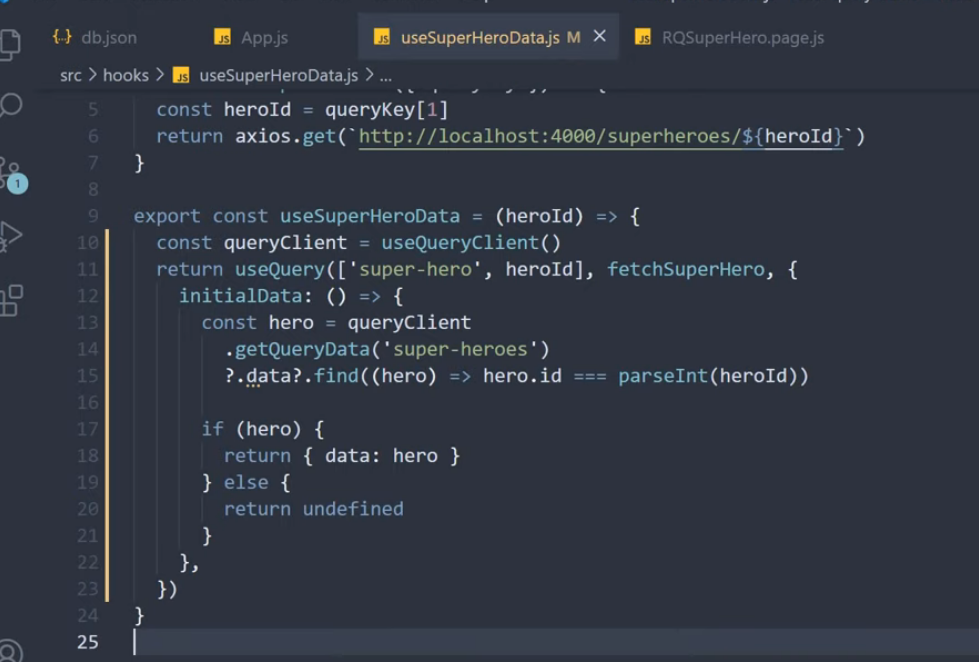
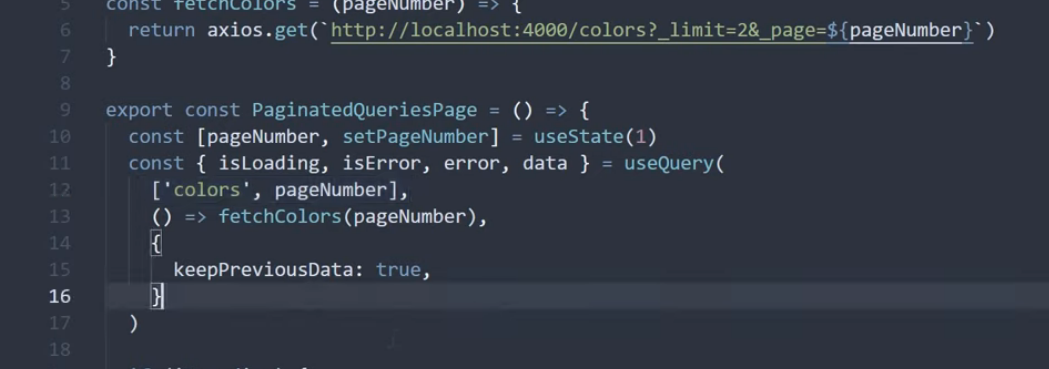
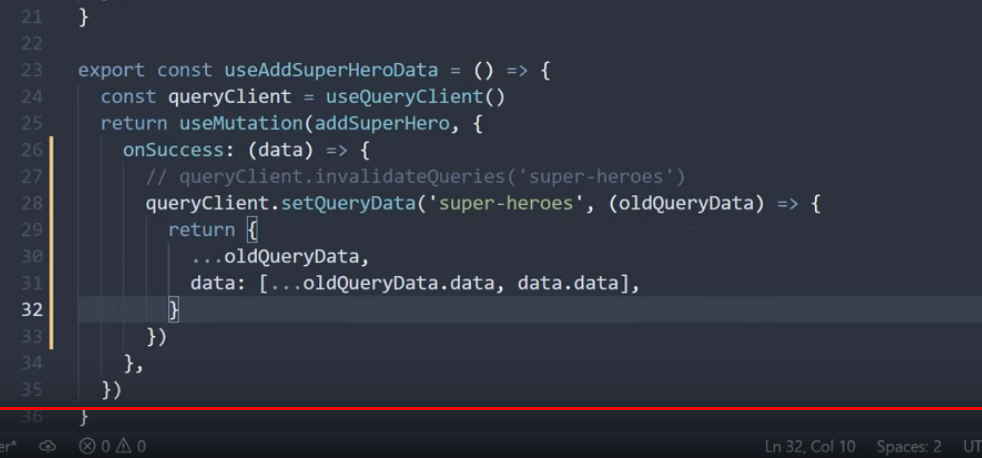
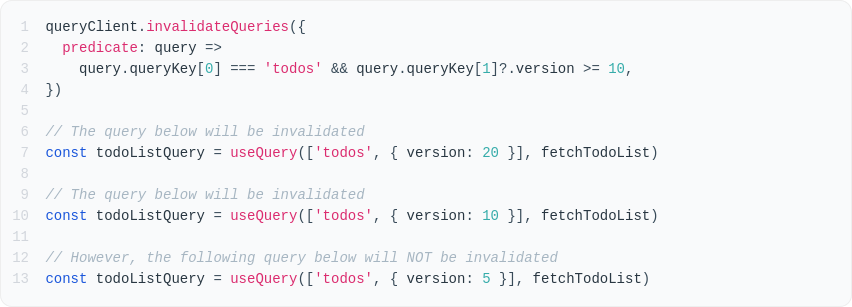
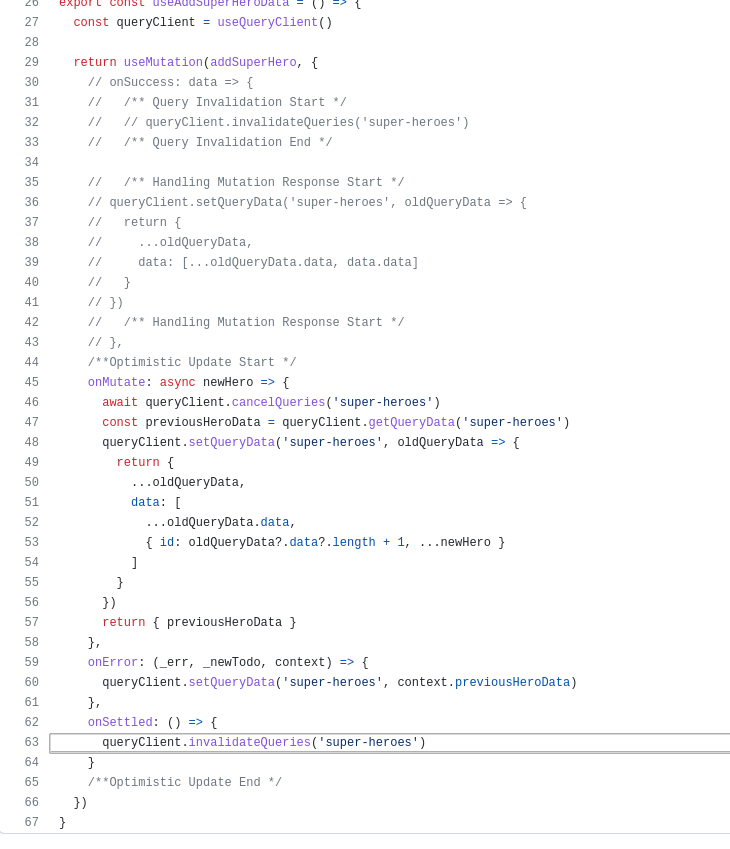
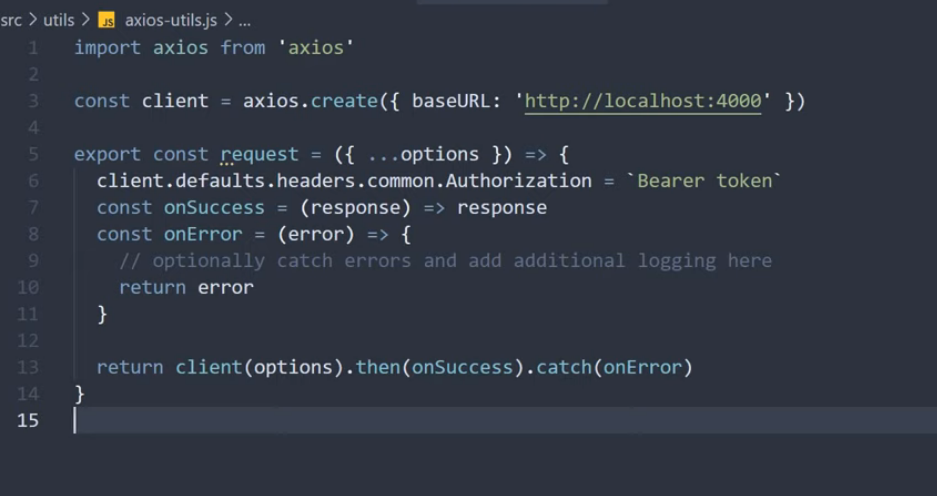
코드 컨밴션이 존재하지 않아, 프로젝트 내에 코드의 일관성이 일치하지 않는 현상이 발생하였다. 그 중 하나로 의존성 주입하는 방식이 거론되어, 의존성 주입 방식의 차이와 실제 오류가 발생하는지를 알아보게 되었다.
의존성 주입 방식에는 크게 3가지가 존재한다.
필드 의존성
생성자 의존성
setter 의존성
1. 필드 의존성 주입 (Field Injection)
public class A {
@Autowired
private AService aService;
}
2. setter 의존성 주입 (Setter based Injection)
public class A {
private AService aService;
@Autowired
public void setAService(AService aService){
this.aService = aService;
}
}
3. 생성자 의존성 주입 (Constructor based Injection)
// 의존성 주입 대상이 한 개일 경우, 생성자에 @Autowired 어노테이션을 붙이지 않아도 된다.
public class A {
private final AService aService;
public A(AService aService){
this.aService = aService;
}
}
// 의존성 주입 대상이 2개이상인 경우, 생성자에 @Autowired 어노테이션을 붙여야 한다.
public class A {
private final AService aService;
private final BService bService;
@Autowired
public A(AService aService, BSerivce bService){
this.aService = aService;
this.bService = vService;
}
}
B. 차이점: Bean 주입 순서
1. 필드 의존성 주입
주입 받으려는 빈의 생성자를 호출하여, 빈을 찾거나 빈 팩토리에 등록한다.
생성자 인자를 사용하는 빈을 찾거나 만든다.
필드에 주입한다.
2. Setter 의존성 주입
주입받으려는 빈의 생성자를 호출하여, 빈을찾거나 빈 팩토리에 등록한다.
생성자의 인자를 사용하는 빈을 찾거나 만든다.
주입하려는 빈 객체의 수정자(setter)를 호출하여 주입한다.
🟥 필드, Setter 의존성 방식은 런타임에서 의존성을 주입하여, 의존성을 주입하지 않아도 객체가 생성될 수 있다.
3. 생성자 의존성 주입
생성자의 인자에 사용되는 빈을 찾거나 빈 팩토리에서 만든다.
찾은 파라미터 빈으로 주입하려는 생성자를 호출한다.
🟥 객체가 생성되는 시점에 빈을 주입하여, 의존성 주입되지 않아 발생할 수 있는 NullPointerException을 방지한다.
C. 순환 참조
A에서 B를 호출하고, B에서 A를 호출하는 관계를 순환 참조라 한다. 이런 경우가 발생하는 일은 한 프로젝트 내에 관리해야하는 클래스가 많아지는 경우 실수로 발생하게 된다.
@Service
public class Aservice {
@Autowired
private Bservice bservice;
}
@Service
public class Bservice {
@Autowired
private Aservice aservice;
}
필드와 Setter 방식에서는 빈이 생성된 후에 참조를 하기 때문에 애플리케이션이 아무런 오류나 경고없이 구동된다. 실제 코드가 호출될 때까지 알 수 없다는 의미이다.
생성자를 통해 의존성 주입할 경우 BeanCurrentlyInCreationException이 발생한다. 순환참조뿐만 아니라 의존 관계에 내용을 외부로 노출 시킴으로 애플리케이션이 실행하는 시점에서 오류를 확인할 수 있다.
D. 코드의 깔끔함
1. 필드 의존성 주입
@Service
public class Aservice {
@Autowired
private Bservice bservice;
}
장점: 한 필드에 어노테이션을 붙임으로써 생성자를 만들지 않아 코드의 수가 줄어든다.
단점: 필드가 많아질 경우 한 줄씩 어노테이션이 추가적으로 붙게 된다.
2.생성자 주입과 Loombok
매번 생성자를 만들어서 주입하는 것이 코드의 깔끔함을 저해시킨다. 하지만 Lombok을 이용한다면 생성자를 자동으로 만들어준다.
@RequiredArgsConstructor
@Service
public class Aservice {
private final Bservice bservice;
}
RequiredArgsConstructor는 final로 선언된 필드를 가지고 생성자를 만들어준다.
E. final 사용
필드나 setter 방식을 이용시에 final 키워드를 사용할 수 없다.
final 키워드 사용 시 런타임 상에서 의존성이 변경되는 가능성을 제거해준다.
F. 실제 코드 실행 시 발생 상황 관찰하기
@Service
public class A {
@Autowired
B b;
}
@Service
public class B {
@Autowired
A a;
}
@Service
public class A {
private final B b;
public A(B b) {
this.b = b;
}
}
@Service
public class B {
private final A a;
public B(A a) {
this.a = a;
}
}
오류가 발생하지 않았다.
앞에서 한 말이 거짓말일까?
2.6.0 버전 특징
기본적으로 순환참조가 발생하지 않는다.
spring.main.allow-circular-references=true
필드 주입 = 속성 추가후 발생 시 순환참조 오류가 발생하지 않고 그대로 동작한다.
결론
2.6.0 버전 이후부터는 순환참조 오류를 미리 잡아주게 되었다. 순환참조 상의 오류때문에 필드, set방식을 안 쓸 이유는 없다.
생성자 의존성 주입 방식의 이점은 런타임 상에서 bean 객체가 변경되지 않는 것을 선호한다는 이유만 남은 것 같다. 하지만 런타임 상에서 bean 객체를 의도적으로 변경하는 사람이 존재할까? 하지만 이런 생각은 이전에 순환참조를 안 만들면 된다는 생각과 동일하기 때문에, 간단하게 막을 수 있다면 막아두는 것이 좋다고 생각한다.
코드의 깔끔함에 있어서 사람들의 견해가 다르다고 생각한다. 누군가는 어노테이션을 사용함에 있어 깔끔하다고 생각하고, 누군가는 어노테이션이 없는 것에 깔끔함을 느낄 수 있다. 만약에 생성자 주입이 직접 설정해야하는 번거로움이 걱정된다면 final이 있는 필드만 생성자를 만들어주는 @RequiredArgsConstructor를 사용하면 될 것 같다.
set방식도 구현하는 방식만 다르지 필드 의존성 주입과의 단점과 동일하여 위에 논한 것으로 충분하다고 생각한다.
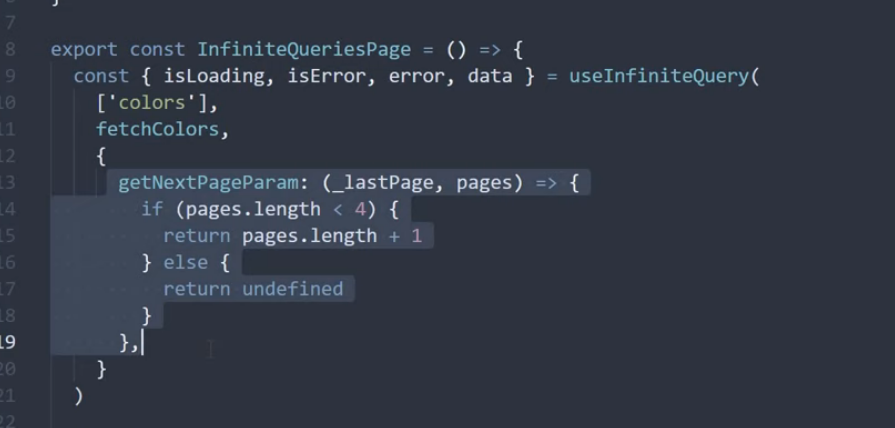
Query에서 isLoading과 isError를 넘겨주어 각 상태에 따라 반환하는 값을 달리하여 화면을 상태별로 다룰 수 있다.
DevTools 띄우기
import React from 'react';
import ReactDOM from 'react-dom/client';
import './index.css';
import { QueryClient, QueryClientProvider } from 'react-query';
import { ReactQueryDevtools } from 'react-query/devtools'
import App from './App';
import reportWebVitals from './reportWebVitals';
const queryClient = new QueryClient()
const root = ReactDOM.createRoot(document.getElementById('root'));
root.render(
<QueryClientProvider client={queryClient}>
<React.StrictMode>
</React.StrictMode>
**<ReactQueryDevtools initialIsOpen={false} position='bottom-right' />**
</QueryClientProvider>
);
// If you want to start measuring performance in your app, pass a function
// to log results (for example: reportWebVitals(console.log))
// or send to an analytics endpoint. Learn more: https://bit.ly/CRA-vitals
reportWebVitals();
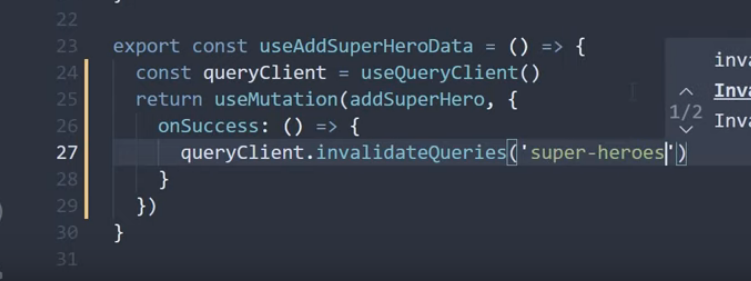
같은 데이터를 매번 받아 사용하면 데이터를 받아오기 때문에 로딩이 발생한다. 그렇기에 캐싱 기능을 사용하면 한번 받아온 데이터를 저장하여 페이지를 로딩 없이 사용할 수 있다.
기본적으로 useQuery 이용 시 staleTime은 0, cacheTime 5분으로 설정되어 캐싱은 자동으로 작동한다.
Stale Time
데이터가 자주 변경되지 않는 데이터들은 네트워크 요청을 하여 데이터를 수시로 가져올 필요가 없다. 그렇기에 데이터 요청 수를 줄이기 위해 staleTime을 조절한다.
특이한 개념 윈도 포커스 ( 탭 이동? )
브라우저 탭을 이동하다 돌아오면 오래되어버린 데이터, steal 상태의 데이터를 다시 가져온다. 하지만 staleTime 시간 동안에는 다시 받아오지 않는다.
다시 정리하자면, 기본적으로 캐싱은 5분으로 진행된다. 이는 곧 메모리에 저장된다는 의미이고, Query를 실행하는 페이지에 이동되어도 이미 데이터가 있기 때문에 로딩이 발생하지 않는다.
하지만 stealTime은 기본 값이 0 임으로 데이터를 받아온 순간부터 받아온 데이터는 썩어버린 데이터 취급을 받게 되고, 이에 따라 윈도우 포커스가 변하여 다시 원래 페이지를 가리키면 데이터 다시 받아온다.
캐시 메모리에 저장된 데이터가 cachTime이 지난 이후에 delete가 된다는 사실도 기억하자. 그렇기에 데이터가 삭제된 이후에는 loading이 발생한다.
const { isLoading, data, isError, error, isFetching } = useQuery(
'text-unique-key',
fetchDataFunction**,{
cacheTime: 5000,
staleTime: 0
}**);
실제 time 명시는 위와 같이 한다. 하지만 기본 값과 동일함으로 적지 않아도 된다.
저는 초반 웹 개발을 배우면서 Vuex(상태 관리 라이브러리)를 사용하니까 사용했습니다. 그래서 상태 관리 라이브러리가 무엇인지 제대로 고민해보지 못한 것 같습니다. 개발을 점점 진행하다 보니 상태 관리가 무엇인지 서버에서 가져온 값은 무엇인지 고민하게 되어 이 글을 작성합니다.
상태 관리란?
상태 관리를 한국어로 할 때 더 직감적으로 이해하는 데 있어 방해가 된다고 생각합니다. 영어로 적을 시 State Management입니다. 여기서 State를 볼 수 있는데 State는 리액트의 useState 훅에서 가리키는 State를 말합니다. 한마디로 페이지나 컴포넌트에서 사용되는 State를 관리하는 라이브러리입니다.
왜 상태를 관리해야 할까?
리액트나 뷰나 하나의 페이지를 컴포넌트 단위로 나누어 만들고 있습니다. 상위 컴포넌트에서 하위 컴포넌트로 데이터를 넘겨줍니다. 또 한번 더 컴포넌트에서 컴포넌트로 데이터를 넘겨주는 경우도 존재합니다. 그렇기에 점점 컴포넌트 깊이가 길어지면 상태를 관리하는 데 있어 불편함이 존재합니다. 아래 영상을 보면 쉽게 이해할 수 있습니다.
예를 들어 매번 props로 데이터를 넘겨줘야한다거나, 상위 컴포넌트에서 어떤 값을 넘겨주었는지 기억을 해야한다거나, 원하는 데이터가 형제 컴포넌트에 있어서 상위 컴포넌트에서 값을 두개로 넘겨줘야한다거나 등의 불편을 느낄 수 있습니다. 그래서 나온 것이 리덕스입니다.
왜 리덕스?
Recoil, Vuex, Ngrx 등 모두 리덕스 개념에서 시작되었으며, 리덕스는 리액트에만 사용하라고 만든 라이브러리가 아닙니다. 위 Gif와 같이 Store란 친구로 Props 대신해 데이터를 뿌려줍니다. 실제 사용하면 Store가 프론트의 DB처럼 느껴집니다.
클라이언트? 서버? 상태 관리?
우아한형제들에서 발표한 React-Query 소개 영상을 통해 서버 상태 관리 단어를 처음 봤습니다. 그리고 리덕스와 비슷한 라이브러리들이 클라이언트 상태 관리란 것도 처음 들었습니다. 클라이언트 상태 관리? 서버 상태 관리? 이게 무슨 차이일까요?
서버 상태 관리 라이브러리 React-query/Swr
SWR 라이브러리를 사용해보지 못해 모르지만 react-query는 사용해봐 알고 있습니다. 주식을 생각해보면 주식의 데이터는 값이 계속 변동이 되어야 합니다. 바로 돈과 직결되는 문제가 발생하기 때문입니다. 그렇기에 이 데이터를 서버의 데이터베이스의 상태와 동일하게 유지되어 좋습니다. 그렇기에 주기적으로 서버 데이터를 프론트로 가져와야합니다. 이 과정의 코드 구현을 해소해주는 라이브러리가 서버 상태 관리입니다.
클라이언트 상태 관리 라이브러리란?
그럼 클라이언트 상태 관리 라이브러리는 무엇일까요? 기존 리덕스를 사용하는 프로젝트들을 보면 action에 axios를 사용하여 값을 업데이트했습니다. 이런 식으로 화면에 보여주는 값들을 action을 통해 가져와 관리하는 라이브러리입니다
왜? 서버 상태 관리 라이브러리가 존재해?
서버에서 가져온 데이터는 서버에 있는 데이터와 동일할까요? 그럴 수도 있고 아닐 수도 있습니다. 그렇기때문에 주기적으로 데이터를 가져와 서버 상태와 동일하게 유지해야합니다. 그런데 리덕스에서는 이렇게 주기적으로 호출하여 가져오려면 따로 코드를 작성해야합니다. 그렇기 때문에 이를 편리하게 해주는 라이브러리가 나왔습니다.
우리는 서버에서 가져온 값을 Props로 많이 넘기고 있기 때문에 UI에 사용되는 State보다 서버에서 가져온 State를 많이 사용하고 있다고 생각합니다.
혼용해도 될까? 하나만 써야할까?
처음에는 리액트 쿼리와 리덕스를 같이 사용하려고 했습니다. 하지만 생각해보니 동일한 데이터를 같이 캐시에 담아두면 메모리 낭비가 발생한다고 생각했습니다. 리액트 쿼리를 사용하는 게 서버에서 값을 가져와 관리하기 편하다고 느낍니다. 그래서 리액트쿼리를 사용하고, 클라이언트 간에 UI State 관리가 힘들어진다면 그때 리덕스를 사용할 예정입니다.(사실 리덕스보다 Zustand를 사용할 생각입니다.)
이전 이집트인의 곱셈에서 이진수를 잘 모르고 있다는 느낌을 받았다. 아마 이진수를 잘 몰라도 코딩은 가능하겠지만, 알면 더 잘할 수 있지 않을까? 아님 남들보다 조금 더 간지나는 코딩이 가능하지 않을까? 이후 이 글자색으로 현실의 수에 비유하여 공감시켜드리겠습니다.
이진수
논리회로 책에서 이진수를 아래와 같이 설명한다.
2진수에서는 낮은 전압 레벨(0V)을 0, 높은 전압 레벨(5V)을 1로 각각 대응시킨다. 그와 같이 표현되는 0과 1의 값을 가지는 기본 데이터 단위를 2진 숫자고 하며 간략히 비트라고 부른다.
우리가 과학 시간에 배운 전구를 키는 회로를 생각해보면, 전구가 켜지면 1, 전구가 꺼지면 0이다. 논리회로를 배웠고, 마이크로 프로세서 수업을 들었음에도 불구하고 전구 하나만 생각했고, 그냥 그게 2진수가 비트다. 비트가 여러개 보여서 바이트고 이런 식으로 생각했다. 단순하게 지식만 익힌 것 같다.
지금 생각해보니, 전구가 2개면 우리가 가지는 상태는 4개이다. (전구 = 비트) 전구가 3개면 상태가 8개다. 당연한 이야기를 하고 있다. 10진수에서 100을 10으로 나눠보자. 100/10 = 10이다. 1000을 10으로 나누면 100이다. 패턴이 보인다. 10진수에서 10으로 나눈다는 건 10진수에서 뒤에서 하나 자리수를 뺀 것이다. 예를 123에서 10으로 나누면 12이가 된다. 1000을 10^2으로 나눈다면 뒤에서부터 2자리를 뺀 것이다.
10진수에서 10^n으로 나눈다는 것은 뒤에서부터 n개 뺀 것(Shift)이다.
2진수 또한 다를까? 2진수도 동일하다. 8진수도 동일하다. 16진수 또한 동일하다. 2진수에서의 Shift 연산이 2진수이기 때문에 왼쪽으로 움직이면 2배가 되고, 오른쪽으로 가면 2로 나누는 것이 된다. 그리고 이집트인의 곱셈에서 이진수로 41을 표현하였을 때 0010 1001이다. 이집트인의 곱셈에서 비트 1이 존재하는 부분에 따라 a의 2배한 값을 더 했었다. (41은 2^6 + 2^4 + 2^1) 각 숫자의 의미를 제곱의 의미로 가진다고 생각하고, 그 의미를 가진 전구가 켜져있다고 생각하니 왜 41이 저렇게 표현이 되고, a의 2배한 값을 더 한다는 의미를 이해했다.
2진수에 대해서 알고 있다면 Shift 연산이 왜 2배인지 2로 나누는지 알면서 쓸 수 있지 않을까? 또한 이집트인의 곱셈의 경우 또한 방법을 이용만 하는게 아니라 이해하여 사용할 수 있지 않을까 싶다.
이집트 알고리즘은 인류 최초로 기록된 알고리즘 중 하나다. 빠른 곱셈 알고리즘, 빠른 나눗셈 알고리즘이다.
먼저 알아둬야하는 상식은 고대 문명의 알고리즘이기 때문에 자릿수 개념과 0을 표현하는 방법이 없었다. 자릿수 개념이 없었다는 말이 나중에 나올 이진수와 비슷하다고 생각이 든다.
먼저 곱셈은 1) 1로 곱하기, 2) 1보다 큰 수로 곱하기, 2가지로 정의하여 나눌 수 있다.
1) 1a = a
2) (n+1)a = na+a
먼저 우리가 알고 있는 일반 상식? "곱셈은 덧셈을 여러번한 것이다"를 구현해보자. => 덧셈을 n-1번 반복해보는 알고리즘(n-1번 반복하니 시간 복잡도는 O(n)라고 알 수 있다.)
우리는 덧셈을 배울 때 결합 법칙을 배웠기 때문에 덧셈의 횟수를 줄일 수 있다.
중학교 때 배우는 간단한 덧셈의 결합 법칙을 코드에 녹여낸다는 사실 자체가 신비롭다. 다음은 4a = ( (a + a) + a) +a 덧셈을 4번을 한다. 여기서 결합 법칙을 응용한다면, 4a = (a+a) + (a+a), a+a를 한 번하고 a+a끼리 한번 더해주면 총 2번을 한다. 다시 씹어 먹어보자. 4a = (a+a) + (a+a) <= a를 2배로 하고 2배한 만큼 더한다.
우리가 곱셈 시에 a 하나만을 이용하여 곱하는 것은 아님으로 일반적인 식을 n*a라고 했을 때, n을 반으로 줄이고, a를 2배로 키워서 2를 거듭제곱한 횟수만큼 더한 값을 만든다고 할 수 있다. (물론 책에서 이렇게 말한다.)
# 왜 n을 반으로 줄일까?
n = 41, a = 59
1 59 2 118 4 236 8 472 16 944 32 1888
이 부분이 제일 어려운 것 같다. 일단 먼저 자릿수 개념이 없던 이집트에서 수를 어떻게 표기하였는지 모르겠다. 또한, 이 알고리즘을 소개한 책에서 이집트에서 어떠한 방식으로 수를 표기하였다고 추가 설명이 없다. 그럼으로 자릿수 개념과 0에 대한 개념이 없는 이집트에서 이진수를 이용하여 표기했다고 가정해보고 41을 2진수로 표기한다.
0010 1001
위에 비트를 보고 41을 2의 거듭제곱으로 표현했다고 말할 수 있다. 41은 2^6 + 2^4 + 2^1이기 때문이다. # 책을 보고 이렇게 분석한 것뿐이지 실제로 이런 생각을 스스로 할 수 있을지 걱정이다.
위에서 생각한 결합 법칙을 이용한 알고리즘을 코드로 작성한다면 아래와 같이 할 수 있다.
여기서 덧셈 횟수를 구해보면 #+(n) = ceil(log n) + ( v(n) -1 ) 와 같다. log n의 이유는 재귀함수로 함수가 돌아가며, 한번 돌 때마다 n의 수가 반절씩 줄어들기 때문이고, v(n)은 홀수인 경우의 수를 의미한다. 거기에 n이 1일 때를 빼줌으로 -1을 한다.
"알고리즘 공부를 하면서 자료구조에 대해서 공부를 해야한다"란 말을 많이 듣는다. 자료구조 라이브러리는 이미 구현되어있는데, 실제 구현 방법에 대해 알고 있는 것이 좋다고 한다. 이유로는 어떻게 돌아가는지를 알기 때문에 실제 구현 시에 도움이 된다고 하는데, 조금 기분이 이상하다.
우리는 이미 배열이란 자료구조를 애용한다.
"배열 없이 못 살아"란 말을 할 정도로 배열 자료구조를 많이 사용한다. 조금 코딩하다보면 배열을 찾게 된다. 이처럼 다른 자료구조들도 친근해야하는 것이 중요한 게 아닐까? 친근하다의 기준이 무엇일까? 많이 이용해봤기 때문에 그 자료구조를 적재적소로 이용할 수 있다는 뜻일 것이다. -> 적재적소로 이용하기 위해선 무엇이 필요할까? 어떻게 구현되어있는지 알고 있어야 가능하다.
스택의 개념
스택은 유명한 Stack이란 게임과 같다.
아님 롤에서 나오는 나서스 스택과 같다.
여기서 문제가 생긴다. 스택은 단순히 쌓는 친구야! 맞아! 그리고 처음 쌓은 것은 마지막에 나오지! 바로 선입후출, 후입선출이야!!
그리고.. 내 고정 관념은 선입후출로 굳어졌다.
무조건 쌓는다!란 생각때문에 일단 스택에 데이터를 넣고 본다. 그러니까 스택을 쓴다는 것은 데이터를 넣고 본다. 그리고 빼내면서 사용한다. 선입선출 말 덕분에 방법이 하나로 굳어진다. 넣을 때 연산을 할 수 있지 않을까란? 생각을 해보자. 추후 이어지는 글에서 자세하게 다뤄볼 생각이다.
스택 구현 방법론
스택뿐만 아니라 자료구조를 구현할 때 여러가지 생각이 든다. 1. 내 실력이 좋지 않다. 2. 정해진 방법이 없다.이다. 코딩 시에 정해진 방법이 없으면 더 힘들어진다. 맞는 방법이 없으니까!! 물론 나도 정답을 가지고 있지 않지만, 현재 실력에서의 방법을 정해서 정리해보려고 한다.
1. 정적 배열 이용
C++은 기억이 가물 가물하지만, 일단 시도한 바에 따르면 배열 길이의 초기화를 배열 선언시 해줘야한다. Java는 배열을 선언하고 나중에 배열의 길이를 초기화가 가능하다.(와.. 부럽다)
컴파일 에러가 없으니 된다고 본다.
Java로 한번 짜봐야 겠다.
타입이 여러가지로 사용이 가능하니, 배열의 이름을 지어주는 것이 제일 애매하다.
C++로 짠다면 아래와 같이 작성한다.
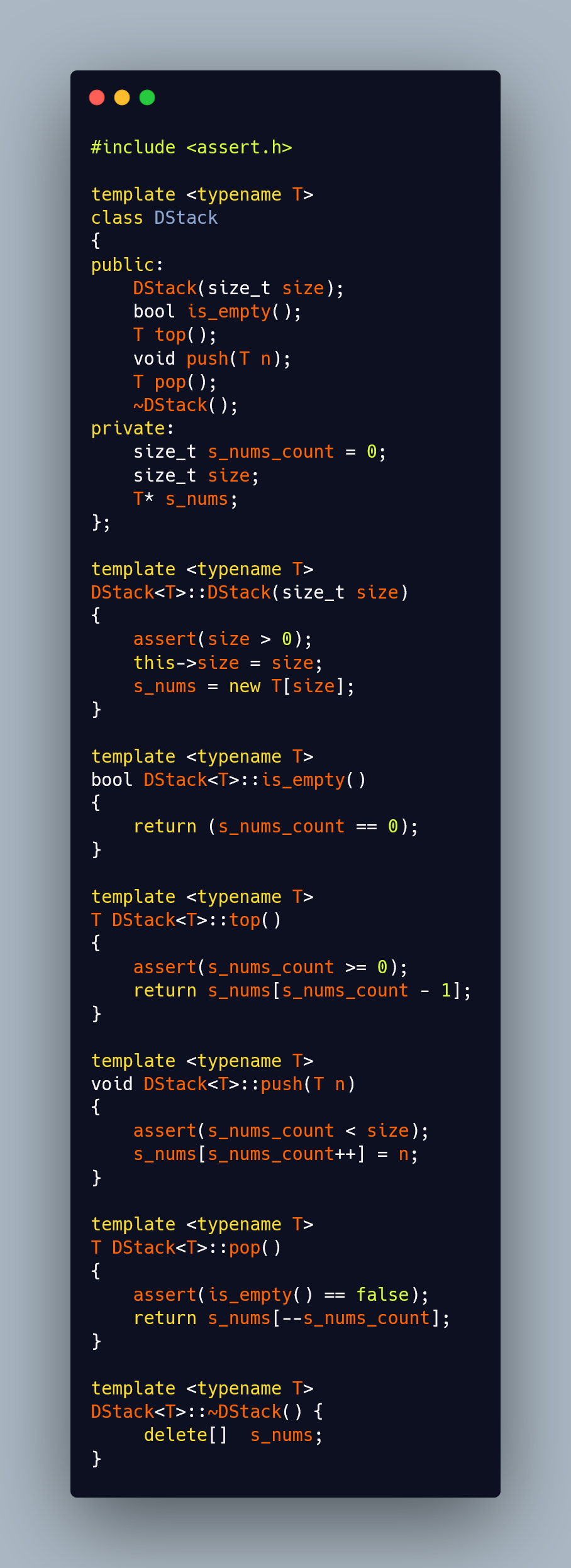
2. 동적 배열(포인터) 이용
비주얼 스튜디오에서 위에 올린 클래스랑 이름이 동일하다고 에러 발생!을 알려줘서 이름을 Dstack이라고 바꿨다. 코드를 보면 알겠지만, 동적 생성 부분만 다르지 거의 비슷하다.
정적과 동적의 차이
정적은 이미 내 스택메모리에 메모리를 쌓는 행위이기 때문에 빠르다. 동적은 내 힙 메모리에 쌓기 때문에 느리다. 실제 알고리즘 문제를 풀 때에 정적을 사용할까? 동적을 사용할까? 의문이다. 만약에 회사 면접에 가서 알고리즘 문제를 풀 때 스택을 구현해야한다면 정적으로 구현해야할까? 동적으로 구현해야할까? 모르겠다. 아직 레벨이 부족하기 때문에 모르는 것일까?
끝
어떤 언어로 구현하는지는 중요하지 않다. 이 자료구조를 배열처럼 익숙해지려면 직접 문제에 적용을 해봐야하니 다음 글에서 문제에서 스택을 어떠한 방식으로 이용하였는지 분석해보자!