
 Spring Boot Security 5 - Oauth2.0 구글 로그인 (HTTP BASIC 탐방) - 1
Spring Boot Security 5 - Oauth2.0 구글 로그인 (HTTP BASIC 탐방) - 1
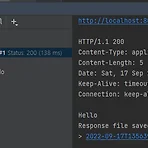
단순하게 Spring Boot Security 5에 대해 코드만 작성하는 글이 아니라, 이해를 위한 글을 작성하기 노력하고 있습니다. Oauth2.0을 알아보기 전에 기본인 HTTP Basic 로그인에 대해 알아보겠습니다. 1. 종속성 추가하기 먼저 종속성을 추가해줍니다. 기존 프로젝트에 시큐리티만 추가하면 됩니다. lombok은 코드를 간편하게 쓰기 위해 추가했습니다. dependencies { implementation 'org.springframework.boot:spring-boot-starter-security' implementation 'org.springframework.boot:spring-boot-starter-web' compileOnly 'org.projectlombok:lombok..
 백준 C++ 숫자고르기 골5 문제 풀이
백준 C++ 숫자고르기 골5 문제 풀이
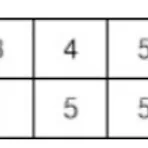
https://www.acmicpc.net/problem/2668 2668번: 숫자고르기 세로 두 줄, 가로로 N개의 칸으로 이루어진 표가 있다. 첫째 줄의 각 칸에는 정수 1, 2, …, N이 차례대로 들어 있고 둘째 줄의 각 칸에는 1이상 N이하인 정수가 들어 있다. 첫째 줄에서 숫자를 적절 www.acmicpc.net 이 글을 읽는다면 문제는 이미 다 알고 있다고 생각합니다. 구해야하는 정답은 첫 번째 줄에서 뽑은 수와 두 번째에서 뽑은 수가 같은 집합의 최대 크기이다. 두번째 줄에서 주어진 수에서 인덱스번호가 없는 2와 7은 첫번째 줄에서 선택할 필요가 없다. -> 왜냐하면 2와 7을 뽑아봤자 2번째 줄에 2와 7이 없기 때문에 같은 수를 뽑을 수가 없기 때문이다. 일단 이해하기 쉽도록 그래프를 ..
 백준 1, 2, 3 더하기 5 문제 분석
백준 1, 2, 3 더하기 5 문제 분석
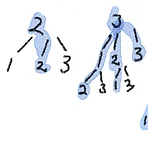
일단 문제를 확인해보면 1부터 3까지 총 3 가지 수로 주어진 N의 더하기 경우의 수를 구하는 문제임을 알 수 있다. 조건이 있는데 연속된 수를 사용하면 안 된다란 조건이 있다. => 곧 힌트란 의미. 먼저 이를 어떻게 구하는 지 고민을 해보면 완전탐색을 생각할 수 있다. 각 경우의 수가 총 2개이다. 1 깊이에서 3개, 2 깊이에서 2개씩 총 6개, 3 깊이에서도 2개씩 총 6*2 12개이다. 4 깊이에서는 24개 결국 깊이에서의 경우의 수가 3, 6, 12, 24 순으로 늘어난다. 무슨 수열인지는 모르겠지만 자신의 앞의 수 * 2씩 늘어난다. 딱 봐도 엄청 느리다. 그래도 수식을 구해야하니까 수열에 공통적으로 3이 곱해져 있으니, 앞으로 빼보니 3*2^n 이다. 문제에서는 n이 100,000보다 작거..
Oauth2.0에 대해 작년에 아무런 지식없이 인터넷을 방황하며 코드를 작성했었다. 당시 Nestjs로 작성했었는데 이제는 다른 프레임워크로 작성해야했다. 이번에는 스프링 부트로 oauth를 이용하려고 하고 라이브러리를 찾아본 결과 시큐리티 5에 있는 oauth2.0-client를 이용했다. 어려운 부분은 크게 2가지였다. 1. 트위치 Oauth에 적용하기 2. Oauth2.0에 대한 지식 해결했던 방법 1. 트위치 Oauth2.o에 적용을 해결했던 방법 카카오와 네이버도 스프링 Oauth2.0 라이브러리에서 제공하는 기본 제공자가 아니다. 이 두개의 적용 방법과 트위치 개발자 페이지와 검색을 통해서 해결했다. spring.security.oauth2.client.registration.twitch.cl..
 React-Dropzone 모듈 만들기
React-Dropzone 모듈 만들기
Dropzone이란 라이브러리가 존재하고, 이를 React hook방식으로 사용하도록 만든 것이 react-dropzone이다. 설치 npm install --save react-dropzone yarn add react-dropzone ### 목적 프리뷰가 있고, Drop한 이미지를 삭제할 수 있어야한다. 먼저 react-dropzone의 Preview 코드를 가져온다. import React, {useEffect, useState} from 'react'; import {useDropzone} from 'react-dropzone'; const thumbsContainer = { display: 'flex', flexDirection: 'row', flexWrap: 'wrap', marginTop: ..
 Spring DI 방법론
Spring DI 방법론
https://susuhan.notion.site/Spring-DI-6113d9eefba446c99413d1323abe9276 - 이쁘게 보기 - Spring DI 방법론 글의 목적 필드 의존성 주입과 setter 의존성 주입, 생성자 의존성 주입에 관한 차이를 알아가기 susuhan.notion.site Spring DI 방법론 💡 글의 목적 필드 의존성 주입과 setter 의존성 주입, 생성자 의존성 주입에 관한 차이를 알아가기 A. 문제의 발단 코드 컨밴션이 존재하지 않아, 프로젝트 내에 코드의 일관성이 일치하지 않는 현상이 발생하였다. 그 중 하나로 의존성 주입하는 방식이 거론되어, 의존성 주입 방식의 차이와 실제 오류가 발생하는지를 알아보게 되었다. 의존성 주입 방식에는 크게 3가지가 존재한다...
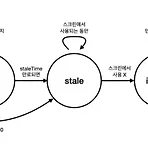 React Query 설명
React Query 설명
React Query 🔥 목적 🔥 : 1. 처음 보는 사람도 이해할 수 있어야 한다. 2. 개발 중에 참고할 수 있는 수준이어야 한다. 상태 관리 라이브러리란? 1. 서버 상태 관리 라이브러리 리액트에는 상태 관리 라이브러리의 큰 종류로 서버 상태, 클라이언트 상태가 존재한다. 클라이언트 상태 관리 라이브러리는 리덕스, 리코일, Zustand 등으로 존재한다. 2. 왜 상태 관리 라이브러리를 사용하나? 리덕스를 사용하는 이유: https://koolreview.tistory.com/119 서버 상태 라이브러리를 사용하는 이유: 간단히 서버의 데이터를 가져와 관리해주는 라이브러리라 생각하면 된다. Client vs Server State Client state 앱 메모리에 유지되고 이를 액세스 하거나 업데..
 클라이언트 vs 서버 (상태 관리브러리)에 대한 생각
클라이언트 vs 서버 (상태 관리브러리)에 대한 생각
왜 우리는 상태 관리를 할까? 아무런 이유 없이 나는 강의에서 사용해서 사용했다 😥 저는 초반 웹 개발을 배우면서 Vuex(상태 관리 라이브러리)를 사용하니까 사용했습니다. 그래서 상태 관리 라이브러리가 무엇인지 제대로 고민해보지 못한 것 같습니다. 개발을 점점 진행하다 보니 상태 관리가 무엇인지 서버에서 가져온 값은 무엇인지 고민하게 되어 이 글을 작성합니다. 상태 관리란? 상태 관리를 한국어로 할 때 더 직감적으로 이해하는 데 있어 방해가 된다고 생각합니다. 영어로 적을 시 State Management입니다. 여기서 State를 볼 수 있는데 State는 리액트의 useState 훅에서 가리키는 State를 말합니다. 한마디로 페이지나 컴포넌트에서 사용되는 State를 관리하는 라이브러리입니다. 왜..