
티스토리 뷰

sometimes referred to as a fair-share scheduler.
Proportional-share is based around a simple concept:
Instead of optimizing for turn-around or response time, a scheduler might instead try to guarantee that each job obtain a certain percentage of CPU time.
lottery scheduling: ← Proportional Share의 좋은 예
The basic idea is quite simple: 다음 실행될 프로세스를 추첨을 통해 결정한다. 더 자주 수행되어야하는 프로세스는 당첨 기회를 더 많이 준다.
lottery scheduling
Underlying lottery scheduling is one very basic concept: tickets, which are used to represent the share of a resource that a process (or user or whatever) should receive.
The per-cent of tickets that a process has represents its share of the system resource in question.
Ex) Imagine two processes, A and B, and further that A has 75 tickets while B has only 25.

Lottery scheduling achieves this probabilistically (but not deterministically) by holding a lottery every so often (say, every time slice). Holding a lottery is straightforward: the scheduler must know how many total tickets there are (in our example, there are 100)
The scheduler then picks a winning ticket, which is a number from 0 to 99.
Assuming A holds tickets 0 through 74 and B 75 through 99, the winning ticket simply determines whether A or B runs.
Basic Concepts
Random approaches have at least three advantages over more traditional decisions.
First, random often avoids strange corner-case behaviours that a more traditional algorithm may have trouble handling.
Second, random also is lightweight, requiring the little state to track alternatives.
Finally, random can be quite fast.
As long as generating a random number is quick, making the decision is also, and thus random can be used in a number of places where speed is required.
- Random number generator를 만드는 것은 굉장히 어렵다. -
Ticket Mechanisms
One way is with the concept of ticket currency.
Currency allows a user with a set of tickets to allocate tickets among their own jobs in whatever currency they would like. the system then automatically converts said currency into the correct global value.
For example, assume users A and B have each been given 100 tickets.
User A is running two jobs, A1 and A2, and gives them each 500 tickets (out of 1000 total) in User A’s own currency. User B is running only 1 job and gives it 10 tickets (out of 10 total).

Another useful mechanism is ticket transfer.
With transfers, a process can temporarily hand off its tickets to another process.
This ability is especially useful in a client/server setting, where a client process sends a message to a server asking it to do some work on the client’s behalf. To speed up the work, the client can pass the tickets to the server and thus try to maximize the performance of the server while the server is handling the client’s request.
Finally, ticket inflation can sometimes be a useful technique.
With inflation, a process can temporarily raise or lower the number of tickets it owns.
Rather, inflation can be applied in an environment where a group of processes trust one another
in such a case, if any one process knows it needs more CPU time, it can boost its ticket value as a way to reflect that need to the system, all without communicating with any other processes
구현(Implementation)
//counter: used to track if we've found the winner yet
int counter = 0;
//winner: use some call to a random number generator to get a value,
// between 0 and the total # of tickets
int winner = getrandom(0, totaltickets);
//current: use this to walk through the list of jobs
node_t *current = head;
//loop until the sum of ticket values is > the winner
while(current) {
counter = counter + current->tickets;
if (counter > winner)
break; // found the winner
current = current->next;
}
노드를 이어준 링크드 리스트 형태로 구현되어있으며 winner에는 랜덤 넘버수가 있고 A는 0-99, B는 100-149,C는 150-399까지 자신의 수를 가지고 있고 링크드형태로 앞에서부터 순차적으로 훑어간다.
counter란 숫자를 A 더하고 B더하고 이런식으로 진행된다. 그리고 counter값이 winner(A,B,C 중 하나)보다 값이 초과된다면 티켓의 당첨자가 된다.
How To Assign Tickets?
One problem we have not addressed with lottery scheduling is: how to assign tickets to jobs?
Why Not Deterministic? → Stride scheduling
random is simple but it occasionally will not deliver the exact right proportions.
Waldspurger invented stride scheduling, a deterministic fair-share scheduler
current = remove_min(queue); //pick client with minimum pass
schedule(current);
current->pass += current->stride;
insert(queue, current);Example: Tree processes A, B, and C with stride values of 100, 200, and 40 and all with pass value initially at 0.
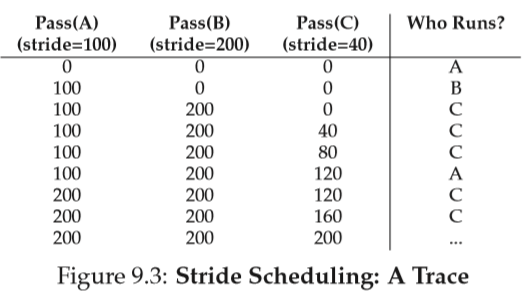
A가 선택이 되서 실행이 된다면 pass값은 A의 stride value 만큼 증가한다.
The Linux Completely Fair Scheduler CFS
To achieve its efficiency goals, CFS aims to spend very little time making scheduling decisions.
Basic operation
Goal: To fairly divide a CPU evenly among all competing process.
vruntime(virtual runtime): A simple counting-based technique. vruntime은 위에 pass와 비슷하다.
As each process runs, it accumulates vruntime.
Int the most basic case, each process's vruntime increases at the same time, in proportion with physical (real) time.
When a scheduling decision occurs, CFS will pick the process with the lowest vruntime to run next.
Q: How does the scheduler know when to stop the currently running process, and run the next one?
A: If CFS switches too often, fairness is increased. If CFS switches less often, performance is increased.
Control parameters
sched_latency: CFS uses this value to determine how long one process should run before considering a switch.
Example:
For n processes, CFS divides the value of sched_latency by n to get a per-process time slice.
CFS then schedules the first job and runs it until it has used the per-process time slice, then checks to see if there is a job with lower vruntime to run instead.

만약 sched_latency가 48초라고 했을 때 이를 프로세스 수로 나눈다. 즉 sched_latency/process number 이렇게 하면 현재 프로세스 수는 4임으로 각 프로세스가 실행 시간은 12초가 된다.
만약 프로세스사 실행 도중 끝나거나 새로운 프로세스가 실행된다면 어떻게 될까? 도중에 끝난다면 각 프로세스당 동작 시간이 늘어날 것이다. 왜냐면 sched_latency는 고정 되어있고 process number가 줄어 각 할당 된 동작시간이 늘어난다. 반대로 새로운 프로세스가 들어왔다면 각 할당된 동작 시간이 너무 작아질 수가 있게 된다. 그렇게 된다면 어떻게 해야할까?
이를 막기 위해서 다른 parameter가 있다. 바로 min_granularity
CFS will never set the time slice of a process to less than this value, ensuring that not too much time is spent in scheduling overhead.
CFS utilizes a periodic timer interrupt, which means it can only make decisions at fixed time intervals.
This interrupt goes off frequently (e.g., every 1 ms), giving CFS a chance to wake up and determine if the current job has reached the end of its run.
CFS also enables controls over process priority, enabling users or administrators to give some processes a higher share of the CPU.
Nice level of a process: The nice parameter can be set anywhere from 20 to +19 for a process, with a default of 0.
Positive nice values imply lower priority, and negative values imply higher priority.
CFS maps the nice value of each process to a weight:

Using Red-Black trees
When the scheduler has to find the next job to run, it should to so as quickly as possible.
Searching through a long list is wasteful.
CFS keeps processes in a red-black tree.
CFS keeps only running (or runnable) processes in the RB tree.
Example: Ten jobs with vruntime 1, 5, 9, 10, 14, 18, 17, 21, 22, 24.

'코딩 관련 > OS' 카테고리의 다른 글
| 운영체제 8 - Mechanism: Address Translation [Memory Virtualization] (0) | 2021.06.11 |
|---|---|
| 운영체제 7 - Interlude(Memory API) [Memory Virtualization] (0) | 2021.06.11 |
| 운영체제 4 - Scheduling [CPU Virtualization] (0) | 2021.06.11 |
| 운영체제 3 - Limited Direct Execution [CPU Virtualization] (0) | 2021.06.11 |
| 운영체제 2 - System Call [CPU Virtualization] (0) | 2021.06.11 |