
티스토리 뷰
세그멘테이션을 사용하지 않고 페이지 테이블을 줄이는 방법을 생각해보자.
멀티 레벨 페이지 테이블은 선형 페이지 테이블을 트리 구조로 표현한다.
→ 매우 효율적이기 때문에 현대 시스템에서 사용되고 있다.
멀티 레벨 페이지의 기본 개념:
- 페이지 테이블을 페이지 크기의 단위로 나눈다.
- 페이지 테이블의 페이지가 유효하지 않는 항목만 있으면, 해당 페이지를 할당하지 않는다.(할당하지 않는다 → PTE를 만들지 않는다)
3.Page directory란 자료구조를 사용하여 페이지 테이블 각 페이지의 할당 여부와 위치를 파악한다.
페이지 디렉터리는 페이지 테이블을 구성하는 각 페이지의 존재 여부와 위치 정보를 가지고 있다.

좌측 그림은 전형적인 선형 페이지 테이블이다. 페이지 테이블의 중앙부에 해당하는 주소공간을 사용되고 있지 않다. 그러나 페이지 테이블에서 항목들이 할당되어 있다.
우측 그림은 동일한 주소 공간을 다루는 멀티 레벨 페이지 테이블이다. 페이지 디렉터리에는 유효한 페이지가 있다.(첫 번째와 마지막). 유효 페이지 두개는 메모리에 존재한다. 이 예를 통해 멀티 레벨 페이지 테이블의 동작을 좀 더 쉽게 알 수 있다.
선형 페이지 테이블에서 사용되었던 페이지들은 더 이상 필요없고, 페이지 디렉터리를 이용하여 페이지 테이블의 어떤 페이지들이 할당되었는지를 관리한다.
간단한 2 level 테이블에서, 페이지 디렉터리의 각 항목은 페이지 테이블의 한 페이지를 나타낸다.
페이지 디렉터리는 page directory entries, PDE들로 구성된다. 각 항목(PDE)의 구성은 페이지 테이블의 각 항목과 유사하다. 유효(vaild)비트와 page frame number, PFN을 갖고 있다. 실제 구현에 따라 추가 구성 요소가 존재할 수 있다.
하지만, PTE와 유효 비트와 PDE의 유효 비트는 약간 다르다. PDE 항목이 유효하다는 것은, 그 항목이 가리키고 있는 PFN을 통해서 페이지들 중 최소한 하나가 유효하다는 것을 의미한다. 즉, PDE가 가리키고 있는 페이지 내의 최소한 하나의 PTE의 vaild bit가 1로 설정되어 있다. 만약 PDE의 항목이 유효하지 않다면, PDE는 실제 페이지가 할당되어 있지 않을 것이다.
Muti-level page tables 장점
첫째, 멀티 레벨 테이블은 사용된 주소 공간의 크기에 비례하여 페이지 테이블 공간이 할당된다. 그렇기 때문에 보다 작은 크기의 페이지 테이블로 주소 고간을 표현할 수 있다.
둘째, 페이지 테이블을 페이지 크기로 분할함으로써 메모리 관리가 매우 용이하다. 페이지 테이블을 할당하거나 확장할 때, 운영체제는 FREE 페이지 풀에 있는 빈 페이지를 가져다 쓰면 된다.<!— 선형 페이지 테이블은 연속된 메모리 공간을 차지한다. 큰 페이지 테이블 4MB의 경우, 해당 크기의 연속된 빈 메모리를 찾는 것이 쉽지 않다. —> <!!— 멀티 레벨 페이징에서는 페이지 디렉터리를 사용하여 각 페이지 테이블 페이지들의 위치를 파악한다. 페이지 테이블의 각 페이지들이 물리 메모리에 산재해 있더라도 페이지 디렉터리를 이용하여 그 위치를 파악할 수 있으므로, 페이지 테이블을 위한 공간 할당이 매우 유연하다. —>
Muti-level page tables 단점
- 멀티 레벨 테이블은 추가 비용이 발생한다. TLB 미스 시, 주소 변환을 위해 두번의 메모리 로드가 발생한다.(페이지 디렉터리와 PTE접근을 위해 한번씩). 선형 페이지 테이블은 한 번의 접근만으로 주소 정보를 TLB로 LOAD한다. 멀티 레벨 테이블은 시간(페이지 테이블 접근 시간)과 공간(페이비 테이블 공간)을 상호 절충(time-space-trade-offs)한 예라 할 수 있다.
즉, 페이지 테이블의 크기를 줄이는데 성공하였으나, 대신 메모리 접근 시간이 증가했다.
TLB 히트 시(대부분 메모리 접근은 TLB 히트다.) 성능은 동일하지만, TLB 미스 시에는 두배의 시간이 소요된다. - 복잡도. 페이지 테이블 검색이 단순 선형 테이블의 경우보다 복잡해진다. 검색을 하드웨어로 구현하느냐 혹은 OS로 구현하느냐 여부와 무관하다. 대부분의 경우, 성능 개선이나 부하 경감을 위해, 우리는 보다 복잡한 기법을 도입한다. 멀티 레벨 페이지 테이블의 경우에는 메모리 자원의 절약을 위해, 페이지 테이블 검색을 좀 더 복잡하게 만들었다.
예제

개념을 이해하기 위해서 예제를 하나 살펴보자.
14bit 가상 주소 공간이 있고 주소 공간은 2^14bit = 16KB 크기를 갖는다. Page는 64Bite를 갖는다고 생각하자. offset은 Page가 64B이므로 2^6이므로 6비트이며 VPN은 14-6 =8이다.
선형 페이지 테이블은 2^8(256)개 ENTRY로 구성된다. 주소 공간에서 작은 부분만 사용된다 하더라도, 선형 페이지 테이블의 크기는 변하지 않는다.
이 예제에서는 가상 페이지 0과 1은 코드. 가상페이지 4와 5는 힙, 가상페이지 254와 255는 스택으로 이용된다. 주소 공간의 나머지 페이지들은 미사용 중이다.
이 주소 공간을 2단계 페이지 테이블로 구성해보자. 선형 페이지 테이블을 페이지 단위로 분할한다. 전체 테이블은 총 256개의 항목을 갖고 있다. 각 PTE는 4바이트라 가정한다. 페이지 테이블의 크기는 1KB(256*4BITE)이다. 페이지가 64바이트라고하면 1KB 페이지 테이블은 16개의 64바이트로 분할된다. 각 페이지에는 16개의 PTE가 있다.
이제 VPN으로부터 페이지 디렉터리 인덱스를 추출하고, 페이지 테이블의 각 페이지 위치를 파악하는 법을 살펴보자. 페이지 디렉터리, 페이지 테이블의 모두 항목의 배열이라는 것을 기억해야한다. VPN을 이용하여 인덱스를 구성하는 법만 찾으면 된다.
먼저 페이지 데릭터리의 인덱스를 만들어보자. 예제의 작은 페이지 테이블은 256개의 항목으로 16개의 페이지로 나뉘어 있다. 페이지 디렉터리는 페이지 테이블의 각 페이지마다 하나씩 있어야하기 때문에 총 16개의 항목이 있어야한다.
결과적으로 VPN의 4개의 비트를 이용하여 디렉터리를 구성하며, 여기서는 VPN의 상위 4비트를 다음과 같이 사용한다.

VPN에서 page-directory index→PDIndex를 추출한 뒤 →
PDEAddr = PageDirBase+(PDIndex*sizeof(PDE))란 간단한 식을 사용하여
page-directory entry, PDE의 주소를 찾을 수 있다.
페이지-디렉터리의 해당 항목이 무효(inavlid)라고 표시되어 있으면, 이 주소 접근은 유효하지 않다. 예외가 발생한다. 해당 PDE가 유효하다면 추가 작업을 해야 한다. 구체적으로 살펴보자. 이 페이지 디렉터리 항목이 가리키고 있는 페이지 테이블의 페이지에서 원하는 페이지 테이블 항목을 읽어 들이는 것이 목표다. 이 PTE를 찾기 위해서 VPN의 나머지 비트들을 사용한다.
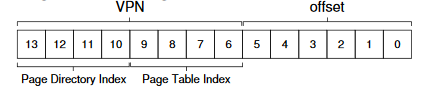
이 page-table index PTIndex는 페이지 자체 인덱스로 사용된다. PTE의 주소를 다음과 같이 계산한다.
PTEAdrr = (PDE.PFN << SHIFT) + (PTIndex*sizeof(PTE)). PTE의 주소를 생성하기 위해서는 페이지-디렉터리 항목에서얻은 페이지-프레임번호(page-frame number, PFN)를 먼저 좌측 쉬프트 연산하고 그 값을 페이지 테이블 인덱스에 합산한다.
이 모든 것이 제대로 작동하는지를 보기 위해, 멀티 레벨 페이지 테이블에 실제 값을 넣은 후에 하나의 가상 주소를 변환해보면 알 수 있다.
'코딩 관련 > OS' 카테고리의 다른 글
| 운영체제 14 - Beyond Physical Memory: Policies [Memory Virtualization] (0) | 2021.06.12 |
|---|---|
| 운영체제 12 - Hybrid Approach: Paging & Segmentation [Memory Virtualization] (0) | 2021.06.12 |
| 운영체제 11 - Faster Translations(TLBs) [Memory Virtualization] (0) | 2021.06.12 |
| 운영체제 11 - Paging [Memory Virtualization] (0) | 2021.06.11 |
| 운영체제 10 - Free Space Management [Memory Virtualization] (0) | 2021.06.11 |